

티스토리 뷰
도입. 기존 테스트의 한계
우리는 일반적으로 테스트 코드를 작성할 때, 정상적인 입력과 예상 가능한 시나리오를 중심으로 검증을 진행한다. 하지만 실제 환경에서는 개발자가 예상하지 못한 다양한 입력이 시스템으로 들어온다. 이러한 입력들은 예상치 못한 오류나 취약점을 유발할 수 있다.
모든 입력을 사람이 직접 테스트 하는 것은 현실적으로 불가능하기 때문에, 무작위 또는 변형된 입력을 대량으로 자동 생성하여 프로그램의 취약점을 탐지하는 Fuzz Testing이 필요하다. 이는 기존 테스트가 놓칠 수 있는 영역을 보완하고 안정적인 시스템을 구축하는데 도움을 준다.
첨언. 해당 블로그 글은 어떤 기술 구현체에 대해 깊이 있게 다루지 않는다. Fuzz Testing의 개념과 유효한 무작위 값을 만들어내는 알고리즘에 대해 간단히 설명한다. 이를 기반으로, JVM 영역에서 사용할 수 있는 라이브러리와 내부 엔진 작동 원리를 간단히 소개한다. 마지막으로 Fuzzer 툴로 발견한 실제 오픈소스 라이브러리의 취약점 발견 사례를 소개하며 마무리한다.
1. NIST의 최소한의 코드 단위 검증 가이드
(Recommended Minimum Standard for Vendor or Developer Verification of Code)
현실적으로 코드 단위에서 어느 정도 안정성이 보장되어야 할까? 정답은 없겠지만, 미국 NIST가 제시한 위 문서를 기준으로 삼아도 좋을 것 같다. 해당 문서는 개발자나 공급업체가 소프트웨어 코드의 보안성과 신뢰성을 확보하기 위해 최소한 수행해야 하는 검증 방법을 정리한 가이드라인이다. 이 중 Dynamic analysis 클래스를 보면, "Run a fuzzer"를 권고하고 있다.

Nist의 가이드에 작성된 Fuzzer의 정의는 최소한의 인간 개입으로, 매우 다양한 입력을 자동으로 생성하여 프로그램을 테스트하는 도구이다. 코드를 작성했다면, 사람이 만든 테스트만으로는 부족하다. Fuzzer를 통해 예상하지 못한 입력까지 자동으로 검증하는 것이 NIST가 제시한 최소 기준이다.
2. Fuzz testing란?
위키백과에 따르면, Fuzz Testing이란 소프트웨어 테스트 기법으로서, 컴퓨터 프로그램에 유효한, 예상치 않은 또는 무작위 데이터를 입력하여 어플리케이션의 취약점을 찾는 테스트를 의미한다. Fuzz Testing의 가장 중요한 핵심 중 하나는, 신뢰 범위를 가로지르는 입력이 중요하다는 점이다. 즉, 우리가 정상이라고 가정한 입력 범위를 벗어난 값이 중요함을 의미한다. 정리하자면, Fuzzing은 이러한 입력을 지속적으로 주입해 숨겨진 버그를 찾아내는 테스트 기법이다.
퍼즈 테스팅은 보편적으로 블랙박스 방법론으로서 사용된다. 블랙박스 방법론이란, 어떤 소프트웨어를 내부 구조나 작동 원리를 모르는 상태에서 소프트웨어의 동작을 검사하는 방법을 의미한다. 즉, 테스트 대상의 내부 구조를 모른체, 입력과 출력값을 바탕으로 테스트 결과를 확인하는 것이다.
따라서, Fuzz Testing은 단지 시스템에 랜덤한 샘플 입력을 제공하며, 정확히 동작하는지보다는 소프트웨어가 충돌 없이 예외를 처리할 수 있는가만 입증할 수 있다. 이 말은 즉, 전체적인 질을 보장하는 툴이며 정형기법이나 철저한 테스팅을 대체할 수 없음을 의미한다.
3. Fuzzer의 무작위 값은 어떻게 만들어질까?
퍼저의 가장 단순한 형태는 완전 랜덤한 값을 생성해서 프로그램에 넣는 것이다. 하지만, 이런 무작위 값이 의미있는 테스트 데이터가 될 수 있을까? 아래 예시 코드를 살펴보자.
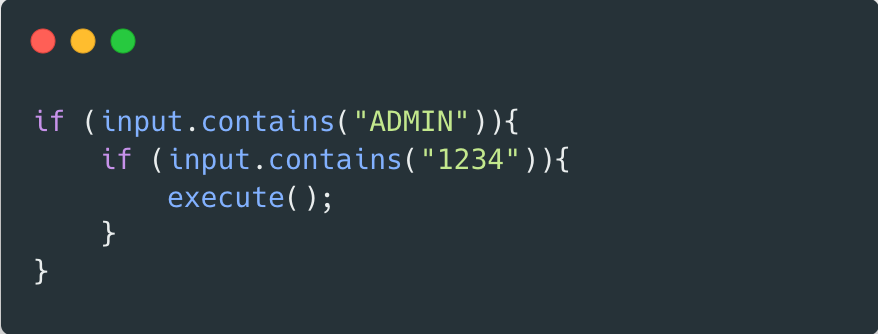
무작위의 입력 값이 들어왔을 때, 위의 execute() 함수가 실행될 확률은 0에 가깝다. 즉, 유효한 입력을 위해서는 코드 커버리지를 기반으로 의미있는 데이터가 들어올 수 있도록 학습되어야 할 것이다.
위의 사례로 보았을 때, 완전히 랜덤한 입력은 다음과 같은 문제들을 초래할 수 있다.
- 프로그램이 초기 validation 단계에서 바로 거부될 수 있다.
- 의미 없는 입력이라 깊은 로직까지 도달하지 못할 수 있다.
랜덤한 결과 값은 많은 테스트를 수행할 수 있지만, 깊이있고, 의미있는 테스트를 할 수 없다. 결국 코드 커버리지가 매우 낮은 테스트가 수행된다. 따라서 가장 성공적인 퍼저는 테스트 대상의 포맷이나 프로토콜에 대한 상세한 이해가 필요하다.
4. Feedback 기반 Fuzzer
결과적으로, 랜덤 Fuzzing으로는 깊은 버그를 찾기 어렵기 때문에, 코드 실행 정보를 활용하는 coverage-guided fuzzing 방식이 등장했다. 이에 따라 현대의 Fuzzer는 다음과 같은 핵심 메커니즘을 기반으로 동작한다.
- coverage-guided: 코드 실행 결과를 기반으로 새로운 코드 경로를 탐색하기 위한 피드백
- corpus: coverage 피드백을 통해 축적된, 의미있는 입력들의 집합
- mutation: corpus을 기반으로 기존 입력을 변형하여 새로운 입력을 생성하는 과정
첨언. 위 3가지 개념은 이후 살펴볼 Jazzer와 내부 엔진인 libFuzzer의 동작 원리를 이해하면 자연스럽게 이해된다. 만약 아직 와닿지 않는다면, 아래 내용을 먼저 읽고 다시 돌아와 보는 것을 추천한다.
현대 Fuzzer는 단순한 랜덤 테스트가 아니라, 코드 커버리지를 피드백으로 활용하여 입력을 점진적으로 발전시키는 진화 기반 탐색 알고리즘이다. 이제 실제 퍼저를 살펴보며, 어떻게 유의미한 입력을 생성하는지 알아보자. JVM 환경에서 동작하는 대표적인 coverage-guided fuzzing 도구인 Jazzer와, 그 내부 엔진인 LibFuzzer를 소개한다.
5. Fuzzer 소개하기. JVM 환경의 Jazzer
유효한 랜덤값을 생성하는 방법에는 다양한 접근이 존재한다. 하지만 이 글에서는 그중에서도 코드 커버리지를 기반으로 입력을 발전시키는 방식, 즉 coverage-guided fuzzing에 초점을 맞춰 살펴본다.
Jazzer는 Java/Kotlin 같은 JVM 애플리케이션에 대해, LibFuzzer 스타일의 coverage-guided fuzzing을 가능하게 해주는 오픈소스 프로젝트이다.

Jazzer는 입력을 계속 mutate(변형)하고, 어느 입력이 새로운 코드 경로(coverage)를 열었는지 추적하고, 더 깊은 경로를 탐색하도록 입력을 발전시키면서 탐지 결과를 수집한다. 즉, 앞서 살펴본 랜덤 무작위 테스트의 단점을 해결하여 유의미한 입력 값을 생성하는 Fuzzer이다.
5-1. Jazzer의 핵심 지원 모드 - Fuzzing mode
Jazzer는 fuzzing을 수행하는 과정에서 목적에 따라 두 가지 모드를 제공한다. Fuzzing mode와 Regression mode가 있다. 아래 Fuzzing mode의 흐름을 이해하는 과정에서 자연스럽게 Regression mode도 이해할 수 있을 것이다.
먼저 Fuzzing mode는 새로운 버그를 찾는 과정이다. coverage-guided fuzzing의 핵심 동작이 수행되는 모드이다. 동작 흐름을 살펴보자.

1. LibFuzzer가 바이트 입력을 만든다.
처음에는 seed(초기) 입력이나 아주 단순한 바이트 배열로 시작한다. 이 입력을 Jazzer에게 전달한다.
2. Jazzer가 그 바이트 입력을 Java 코드로 변환하여 퍼즈 타겟에게 전달한다.
Jazzer는 JVM을 초기화하고, 프로세스 내부에서 퍼즈 타겟(어플리케이션)을 실행시킨다. 그리고 전달받은 바이트 입력을 Java 코드로 변환하여 퍼즈 타겟에게 전달한다. (예를 들어, Junit과 결합할 경우, @FuzzTest 테스트 코드로 전달된다.)
3. Java 어플리케이션(퍼즈 타겟)은 들어온 임의의 입력 값을 기반으로, 코드가 실행된다.
Jazzer는 JVM 안에서 퍼즈 타겟을 실행한다. 실행 중 어떤 분기와 경로가 열렸는지, 코드 커버리지 정보를 Jazzer에게 전달한다.
4. Jazzer가 수집된 코드 커버리지 정보를 LibFuzzer에게 전달한다.
퍼즈 타겟의 실행 이후, Jazzer는 전달받은 코드 커버리지 정보를 LibFuzzer가 이해할 수 있게 변환하여 전달한다.
5. LibFuzzer는 실행 결과를 보고 흥미로운 입력인지 판단한다.
입력을 넣었더니 새로운 코드 경로를 열었거나, 새로운 비교 분기까지 들어갔거나, 예외 혹은 크래시 같은 비정상 동작이 나왔다면 그 입력은 가치가 있다고 판단한다. libFuzzer는 이런 방식으로 coverage를 늘리는 입력을 수집한다.
5-1. 가치 있는 입력은 corpus에 저장된다.
가치 있는 입력은 Input-Directory 내부의 corpus에 저장한다. 여기서 corpus는 지금까지 발견한 유용한 입력 집합이라고 보면 된다. 즉, 그냥 랜덤 데이터를 계속 새로 만드는 게 아니라, 이미 잘 작동했던 유의미한 입력들을 저장해 두고 추후 변형(mutation)하여 다음 입력에 사용한다.
5-2. 예외 혹은 크래시 같은 비정상 동작이 발생한 입력을 crash-input에 저장한다.
예외와 크래시를 발생시키는 입력들은 Input-Directory 내부의 crash-input에 저장한다. 해당 입력 집합들은 변형(mutation)에 활용됨과 동시에 Regression mode에 활용된다. (Regression mode는 Jazzer가 제공하는 2가지 모드 중 하나로, 기존 예외 상황을 재현할 때 사용되는 모드이다.)
6. LibFuzzer는 corpus, crash input에서 입력 하나를 꺼내 살짝 바꾼다.
완전히 처음부터 새 입력을 만드는 게 아니라 유의미한 입력 값이었던 corpus 내부 입력 값을 수정하여 새로운 입력 값을 만들어낸다. 일부 바이트를 바꾸거나, 길이를 늘리거나, 중간 일부를 복사,삭제,삽입하는 방식으로 변형한다. Jazzer 공식 문서는 mutation의 세부 알고리즘을 길게 설명하진 않지만, corpus의 입력 데이터를 변이시켜 coverage를 최대화하는 evolutionary 방식에 기반하고 있다고 설명한다.
여기서 mutation이 필요한 이유는, 예를 들어 "bet"까지는 통과했는데 "betting"여야 다음 분기로 간다면, 기존 입력 근처를 조금씩 바꾸는 mutation이 무작위로 생성하는 랜덤값보다 훨씬 유리하기 때문이다.
7. 위 사이클을 수천,수만 번 반복한다.
실행 → coverage 확인 → corpus 저장 → mutation → 재실행 이 루프가 수천, 수만 번 반복된다. 그러다 예외나 crash가 나면 해당 입력은 재현 가능한 입력으로 저장된다. 이 입력 데이터는 추후 Regression mode에서 사용된다.
6. Jazzer의 대표적인 특징 3가지
지금까지 내용을 정리하자면, 랜덤값 Fuzzing이 갖는 문제를 해결하기 위해 등장한 coverage-guided fuzzing에 대해 살펴보았고, 이어 실제 툴인 Jazzer와 내부 엔진 LibFuzzer를 알아보았다. 이제 이 Jazzer의 간단한 특징만 가볍게 살펴보고 넘어가자. Jazzer는 3가지 대표적인 특징을 갖는다.
1. 대표적인 C++ 환경의 Fuzzer인 LibFuzzer를 JVM 생태계에 결합하도록 도와주는 라이브러리이다.
앞선 흐름에서 살펴보았듯이 Jazzer는 모드 지원과 LibFuzzer의 어뎁터 역할을 한다. 즉, Jazzer는 libFuzzer를 JVM에서 사용할 수 있도록 감싸서 확장한 구조이다.
2. 프로세스를 매번 새로 띄우는 방식이 아닌 같은 프로세스 안에서 빠르게 반복 실행하는 방식이다.
앞선 흐름도를 자세히 살펴보면, LibFuzzer, Jazzer, JVM 타겟 어플리케이션까지 하나의 프로세스 위에서 동작하고 있다. 즉, 각각의 입력마다 프로세스를 생성하여 테스트하는 것이 아닌, 한 프로세스 내에서 수천번, 수만번의 입력 사이클이 반복되기에 fuzzing의 반복 속도가 빠르며 coverage 기반 탐색에 유리하다.
3. JUnit 통합을 제공하여, 테스트 문법 안에서 결합하여 사용하기 용이하다.
가장 실무적이고 실용적인 장점이다. JUnit으로 작성한 기존의 Java 테스트 환경에 통합하기 유리하다. 그래서 일반 테스트와 비슷한 감각으로 fuzz test를 작성할 수 있다. (실제 사용 예시는 아래에서 살펴본다. 얼마나 친숙하게 사용할 수 있는지 체감할 수 있을 것이다.)
7. 적용하기 - 블랙잭 미션 사이클
지난 주차까지 진행한 블랙잭 미션을 기반으로, 실제로 Fuzz Testing을 적용해보자. 간단한 예시로 Player의 이름 입력 값에 대한 fuzzing을 수행하였다. Player의 이름은 아래 검증 규칙을 따르며, 해당 규칙을 기준으로 다양한 입력을 자동으로 테스트하게 된다.

JUnit과 통합하여 fuzzing을 수행할 수 있다. Jazzer는 JUnit 기반에서 동작할 수 있도록 @FuzzTest를 제공하며, 이를 통해 퍼즈 타겟을 테스트 코드 형태로 정의할 수 있다. 앞서 말했다시피, 이처럼 기존 테스트 코드와 유사한 방식으로 fuzz test를 작성할 수 있다는 점은 Jazzer의 실무적인 큰 장점이다.
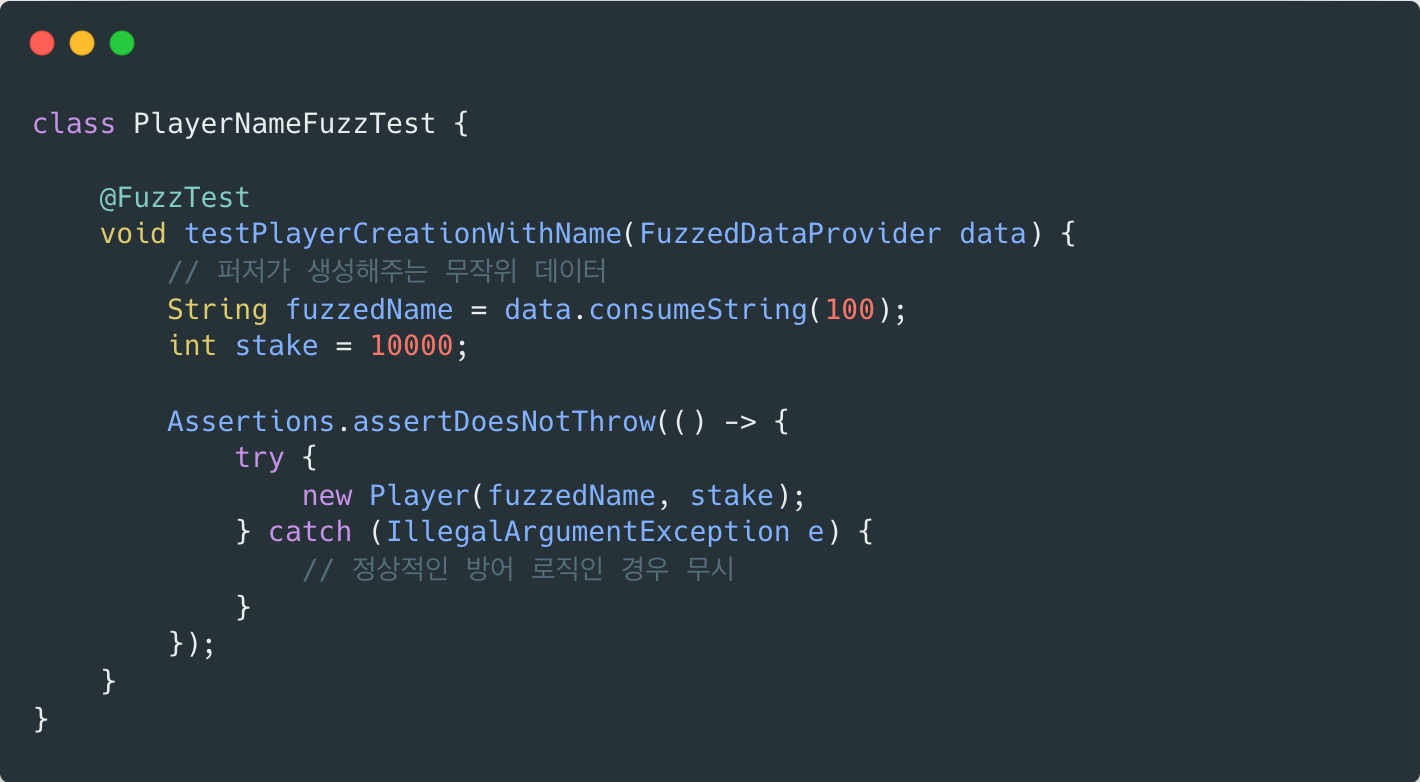
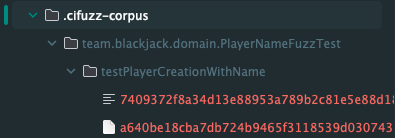
테스트는 아래와 같은 커맨드를 통해 실행할 수 있다. 여기서 JAZZER_FUZZ=1 옵션은 앞서 언급한 Fuzzing mode를 활성화하는 설정이다. 해당 옵션을 지정하지 않으면 기본적으로 Regression mode로 실행되며, 이때는 기존에 생성된 corpus 데이터를 기반으로 테스트가 수행된다. (이 corpus 데이터는 바로 아래 폴더 사진에서 확인할 수 있다.)

테스트를 실행하면, fuzzing 과정에서 생성된 의미 있는 입력들이 .cifuzz-corpus 폴더로 저장된다. 이 corpus는 이후 입력 생성의 기반이 되며, 점진적으로 더 깊은 코드 경로를 탐색하는 데 활용된다.
이제 퍼즈 테스트 실행 결과 로그를 분석해보자.
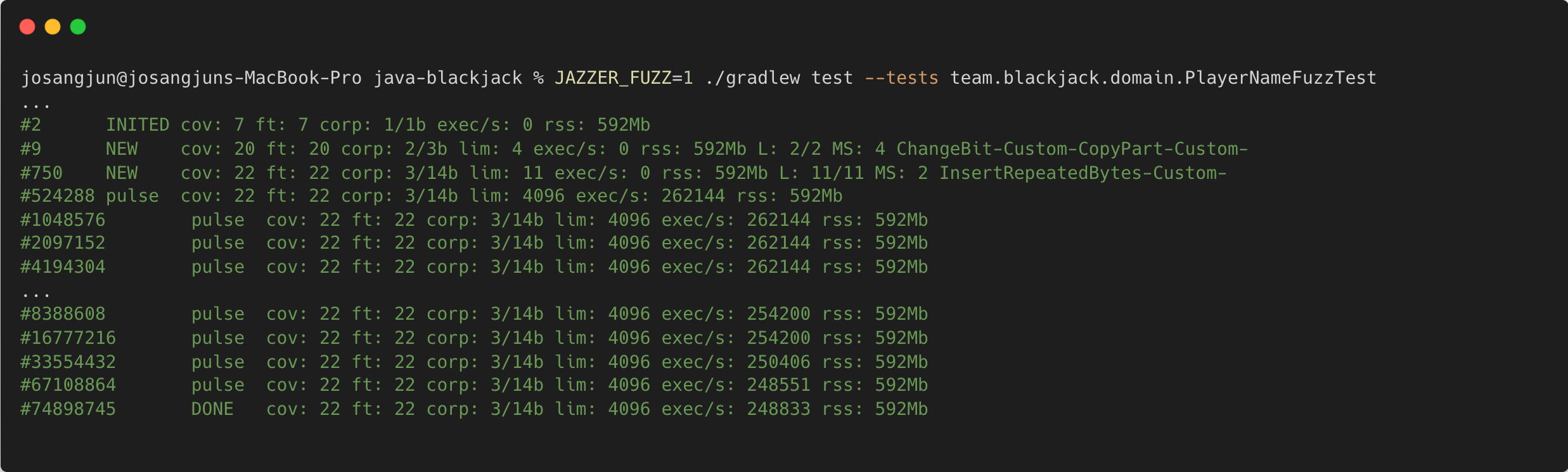
1. 총 실행 횟수
로그의 가장 왼쪽에 표시되는 #{number}는 실행된 테스트 케이스의 번호를 의미한다. 예를 들어, #74898745는 약 7,400만 번의 입력이 실행되었음을 의미한다.
2. 새로운 코드 경로를 발견한 케이스 2건 (New)
퍼저가 실행 중 새로운 코드 경로를 발견하면 NEW 로그가 출력된다. 이때 해당 입력은 유의미한 데이터로 판단되어 .cifuzz-corpus 폴더에 저장된다. 또한 MS(Mutation Strategy) 항목을 통해, 어떤 방식으로 입력이 변형되었는지 확인할 수 있다. 예를 들어, 비트를 뒤집거나(ChangeBit), 바이트를 삽입하는(InsertRepeatedBytes) 방식 등이 사용된다.
3. 코드 커버리지 지표 (cov)
cov는 현재까지 탐색된 코드 커버리지를 의미한다. 즉, 퍼저가 해당 입력을 통해 얼마나 많은 코드 경로를 탐색했는지를 나타내는 지표이다.
4. corpus 상태(corp)
corp: 3/14b는 현재 저장된 유의미한 입력의 개수와 총 크기를 의미한다. 이 경우, 3개의 입력이 총 14바이트 크기로 저장되어 있으며, 퍼저는 이 입력들을 기반으로 새로운 입력을 생성한다.
5. 초당 실행 횟수 (exec/s: 248833)
초당 실행 횟수를 의미한다. 예시에서는 초당 약 24만 번의 테스트가 수행되고 있으며, 이는 앞서 설명한 in-process 방식 덕분에 가능한 성능이다.
테스트 결과 분석
위의 로그를 보면 다음과 같은 결론을 도출할 수 있다. 먼저, 단 몇 분 만에 7,400만 개의 무작위 케이스를 테스트 수행했다. 이는 일반적인 단위 테스트였다면 사람이 일일이 수천만 개의 이름을 입력했어야 했겠지만, 퍼징은 초당 24만건의 속도로 우리가 놓칠 수 있는 엣지 케이스를 검증해냈음을 의미한다. 또한, 결과적으로 DONE이 찍혔다는 것은 예외 케이스가 발생하지 않았다는 점이다.
하지만 DONE이 발생했다는 결과만으로 도메인 로직이 충분히 견고하다고 판단하기에는 한계가 있다. 초기 corpus가 비어있었기에 초반 seed는 무의미한 간단한 바이트로 첫 입력이 실행되었으며, 새로운 코드 경로를 발견한 케이스가 2건 밖에 없었기 때문에 의미있는 seed로 해석하기에는 무리가 있다. 결국, 초반의 의미있는 seed 설정이 테스트에 유의미한 결과를 좌우한다는 사실을 깨달을 수 있다.
결론적으로, 해당 실험 결과는 앞서 언급한 "전체적인 질을 보장하는 툴이며 정형기법이나 철저한 테스팅을 대체할 수 없음을 의미한다." 라는 표현을 반증하기도 한다. Fuzzing Test에 앞서 유의미한 Seed를 전략적으로 잘 설정하는 것이 이 테스트를 의미있게 수행하기 위한 핵심 요건이라고 생각한다.
8. 실제 사례: Google OSS-Fuzz와 Jazzer가 발견한 Log4Shell
Google-Security-Blog:Improving OSS-Fuzz and Jazzer to catch Log4Shell
Improving OSS-Fuzz and Jazzer to catch Log4Shell
Posted by Jonathan Metzman, Google Open Source Security Team The discovery of the Log4Shell vulnerability has set the internet on fire. Sim...
security.googleblog.com
지금까지 우리는 퍼징이 왜 필요한지, 그리고 단순한 랜덤 입력이 아닌 coverage-guided fuzzing이 왜 중요한지 살펴봤다. 이제, Fuzz Testing으로 실제 문제를 해결한 사례인 Log4Shell 취약점에 대해 살펴보자.
Log4Shell은 2021년에 발견된 취약점인데, Java에서 많이 사용하는 Log4j 로깅 라이브러리에서 발생했다. 로그를 남기기 위해 문자열을 처리하는 과정에서, 특정한 형태의 입력이 들어오면 외부 서버와 통신이 발생하는 문제 상황이었다. 이때, 원격 코드 실행까지 이어질 수 있었기 때문에, 로그 문자열 하나로 서버 전체에 피해를 끼칠 수 있는 중대한 취약점이었다. 문제가 되었던 입력은 JNDI lookup 표현식이었다. (구체적인 문제 상황은 CVE 공식 자료 참고)
이처럼 특수한 입력은 우리가 일반적으로 작성하는 테스트 코드에서 거의 등장하지 않는다. 이러한 입력은 우리의 예상 가능한 범위 외에 있기 때문에 일반적인 테스트로 작성하기 매우 어렵다.
Google의 OSS-Fuzzer 환경은 Log4j를 대상으로 퍼징을 돌리면서 계속 다양한 입력을 넣어보는 과정이 있었고, 이 과정에서 외부로 요청이 발생한다는 점을 고려하여 이런 동작을 감지할 수 있도록 기준을 잡아둔 상태로 테스트를 진행했다. 테스트 결과, 퍼징 과정에서 이 조건을 만족하는 입력이 발견됐고 취약점을 재현할 수 있었다.
결국 Log4Shell 사례를 통해, 우리가 예상할 수 있는 범위를 넘어서는 테스트가 필요하다는 점을 알 수 있다. 또한 의미 있는 퍼징 테스트를 위해서는, 재현 가능한 기준을 설정하는 것이 중요하다는 점을 알 수 있다. (이 사례에서는 외부 서버로의 요청 발생 여부가 기준이 되었다.)
참조 래퍼런스
NIST: Recommended Minimum Standard for Vendor or Developer Verification of Code
Google-Security-Blog: ClusterFuzzLite: Continuous fuzzing for all
Google-Security-Blog:Improving OSS-Fuzz and Jazzer to catch Log4Shell
CodeIntelligenceTesting-jazzer
'우아한테크코스' 카테고리의 다른 글
| [OOP] 객체 지향 프로그래밍 개론 (0) | 2026.04.03 |
|---|---|
| [우아한 테크코스 8기] 백엔드 최종 합격 후기 (0) | 2026.01.25 |
| 도메인 검증 프레임워크 Aegis 구현기 7편(완결): 오픈미션 최종 회고록 - Aegis를 만들며 배우고 깨달은 것들 (0) | 2025.11.19 |
| 도메인 검증 프레임워크 Aegis 구현기 6편: 샘플 어플리케이션 작성 및 배포 (0) | 2025.11.18 |
| 도메인 검증 프레임워크 Aegis 구현기 5편: 외부 의존 검증 구현 (0) | 2025.11.17 |